1. Elastic Stack¶
实时搜索、分析和可视化数据、100% 开源
1.1. 分布式日志系统必要性:¶
为什么要做日志系统¶
首先,什么是日志?
日志就是我们的应用程序中产生,可能是应用容器也能是我们的写的程序产生,并且按照一个格式的文本数据。
通常日志是在我们的服务器中产生,按照一定的规则,输出到我们指定的文件中,例如,在操作系统中会有系统日志,安全日志,在应用容器中会有访问日志,在我们的程序中会有程序日志,而这些日志是分散的存储在不同的机器中。
日志对我们的排查故障和分析数据具有非常重要的作用,日志可以从几个方面在系统维护进行辅助:
- 错误排查:往往发生错误的深层原因,例如异常栈会被日志所记录,通过检索日志,可以快速定位错误;
- 数据分析:对日志进一步的分析,可以得出相关的数据,例如,某个商品的 UV,PV;
- 运维诊断:对日志进行分析,可以了解到相关接口的访问量和机器服务负载对比,了解服务器的运行情况。
在我们系统发生故障或者需要对数据进行分析和查找时,我们的运维或开发人员就要登录到不同对应的服务器上,用 grep awk 等工具对日志进行分析和查找,因为负载均衡的原因,我们的服务往往是分布在多个服务实例中,而我们对服务进行排查时需要先确定这块故障究竟是出现在哪一个服务实例,才能进行登录和日志排查。
微服务的日志系统¶
既然日志如此重要,在我们微服务复杂的体系中更不可缺,但是由于微服务的特性,一个大服务被拆分成多个小服务,一个小服务被分布在多台机器中,如何让运维和开发人员能快速定位到某个服务和某台机器?
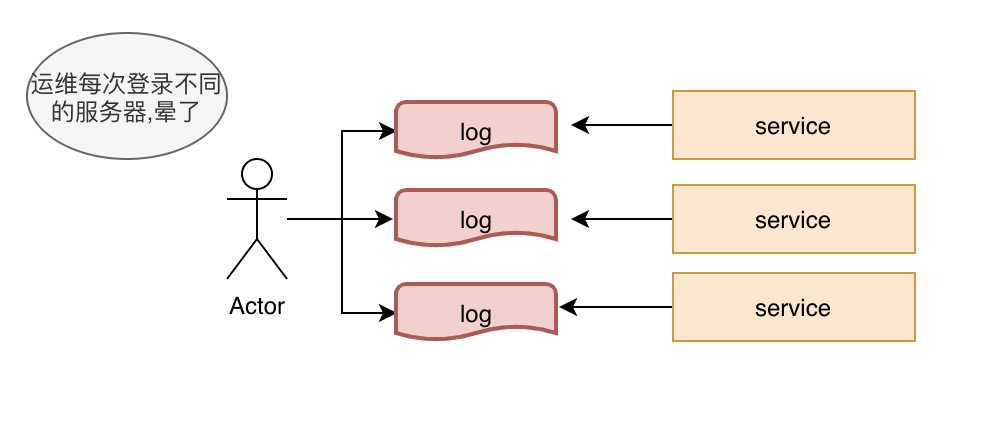
如上图所描述,难道运维人员需要每台机器都登录上去去检索,那就太奔溃了。我们换个想法:把分散的日志想个办法集中起来,让运维和开发到一个集中的地方进行检索和分析。
我们重新设计下,在每台服务器上安装个 agent ,将设定好的 log ,按照一定的规则,上报给日志平台,日志平台有一个可以存储日志数据的存储服务,有一个友好检索查看日志的界面
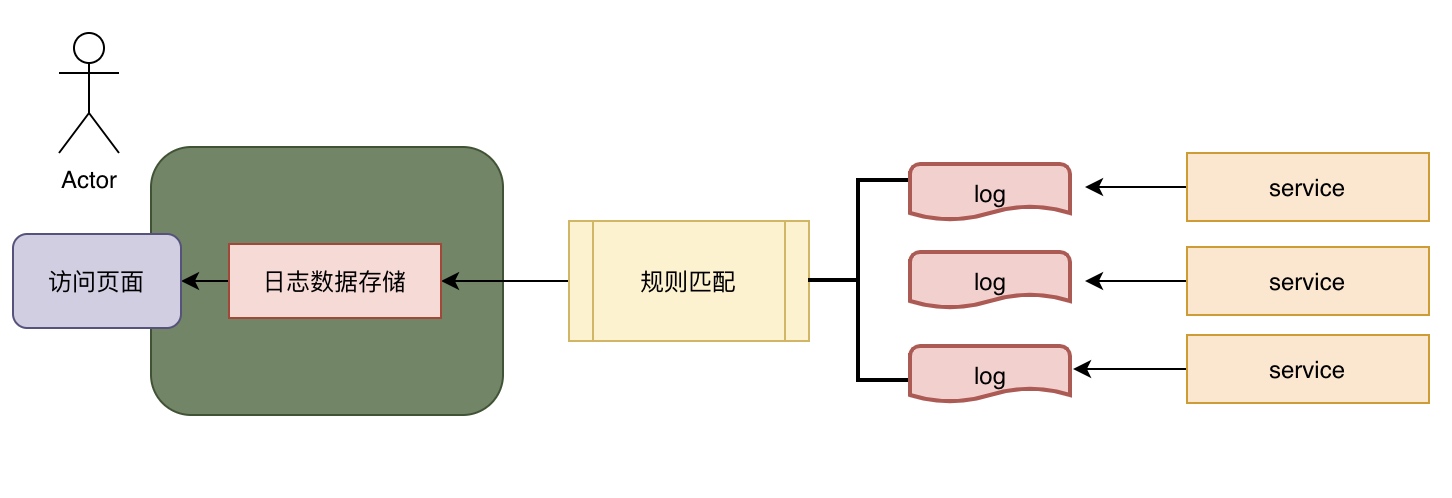
日志平台组件设计图¶
我们做了个设计,整合了日志平台,在原来的基础上添加个 3 大组件,分别是:
- 数据收集和规则匹配 : 在每台服务上添加一个模块 agent,可以动态从各个数据源(日志)收集数据,并对数据进行过滤,分析,丰富统一格式等操作,用网络的方式上报给日志平台;
- 存储和检索引擎:用于接收上报的日志,进行存储,并可以提供检索功能;
- 可视化平台:友好的界面,按照操作人员的操作检索存储引擎,将结果用图表,表格的方式返回给操作人员。
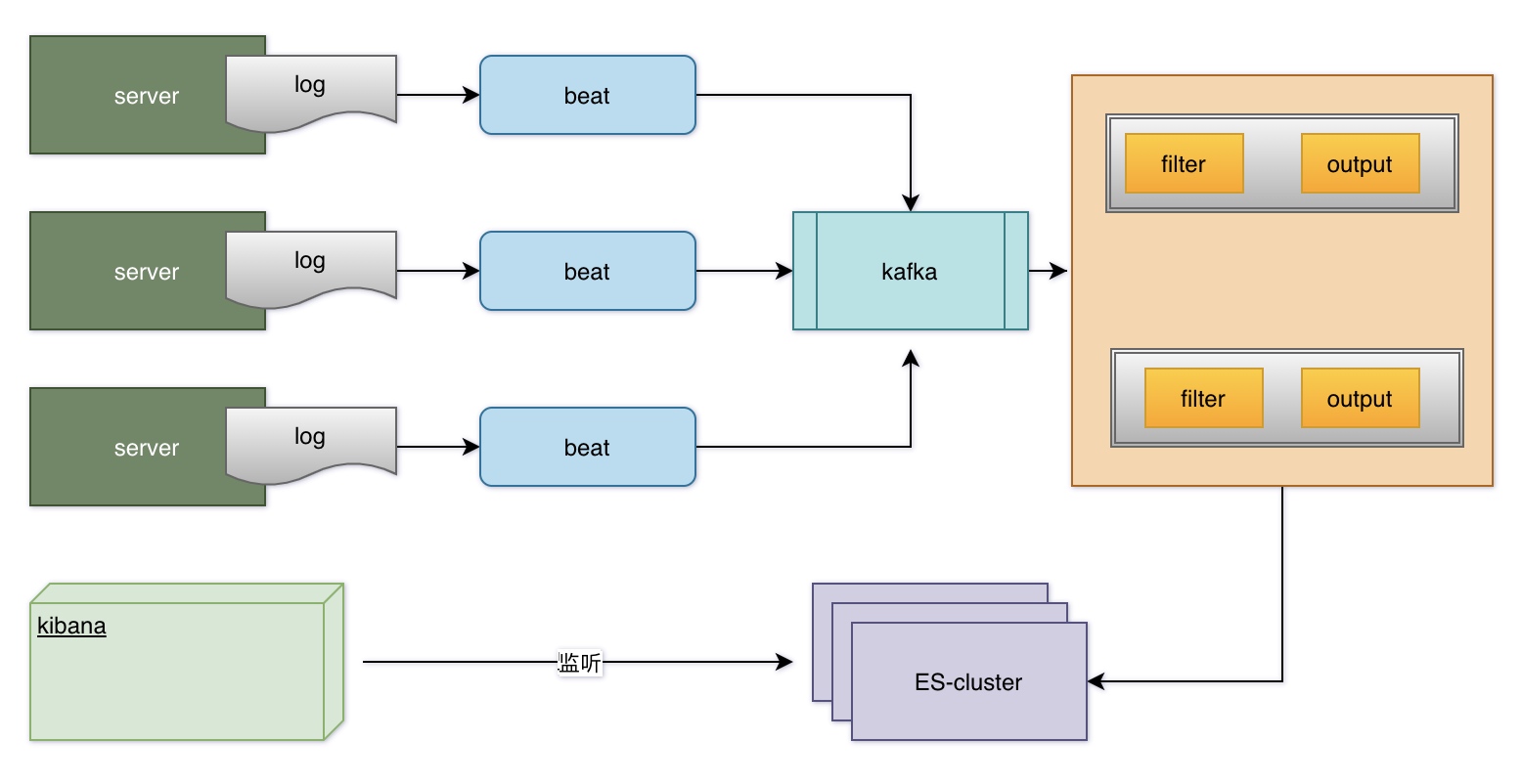
三大组件工作逻辑如下:
- Kibana :可视化化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据
- Logstash :数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用
- Elasticsearch :分布式搜索引擎,基于 Lucene 开发。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。
整体架构图:
1.2. Kibana¶
Kibana 是通向 Elastic 产品集的窗口, 它可以在 Elasticsearch 中对数据进行视觉探索和实时分析
包含多种解决方案, 如搜索、地理位置分析、日志、指标、安全、APM 同时拥有多种功能, 如
- 机器学习
- 数据关联分析
- 规则告警
- 多集群监控
- 报表
- 高级安全
1.3. Logstash¶
Logstash 是 Elastic Stack 的中央数据流引擎, 用于收集、丰富和统一所有数据,而不管格式或模式。 当与Elasticsearch,Kibana,及 Beats 共同使用的时候便会拥有特别强大的实时处理能力。
Logstash入门¶
the dataflow engine
- 开源的流式 ETL 引擎
- 几分钟即可构建 数据流 处理管道
- 具有自适应缓冲的 水平伸缩性 和 弹性
- 数据来源中立性, 支持 众多数据源
- 丰富的周边插件, 目前200多个的第三方集成和处理器
- Elastic Stack自带的监控和管理
Logstash结构¶
| Logstash | ||
|---|---|---|
| Inputs | Filters | Outputs |
| Beats | Structure Transform Normalize |
ElasticSearch |
|
TCP UDP HTTP |
GeoIP Enrichment External Lookups Enrichment CIDR & DNS Lookups |
TCP UDP HTTP |
|
JDBC HTTP Poller |
GeoIP Enrichment External Lookups Enrichment CIDR & DNS Lookups |
Other Storage Queues |
| channel Dead Letter Queues Persistent Queues |
||
备注:
1.At-least-once: 交付保障和基于持久化队列的自适应缓冲2.将错误事件发送到死信队列(dead letter queue)中, 用于离线处理和重放
Logstash模块¶
Immediate Insights with Modules
- 特定数据类型的一键交付
- 从数据到监控面板只需一步
- 自动解析和充实数据
- 默认的监控面板、告警设置、机器学习任务
- 可用的modules
动态管道¶
| 消息处理机制 |
|---|
| Apache Pipeline |
| JDBC Pipeline |
| Netflow Pipeline |
- 带条件和多管道的直接数据流
- 使用身份认证和加密来确保传输安全
- 使用modules来一键交付
- 可轻松构建自定义插件集成和处理器
处理数据¶
codecs & serialize using codecs to serialize/deserialize data
一个示例:¶
input {
file {
// Deserialize new line separated JSON
path => "some/json.log", codec => json_lines
}
}
filter {
}
output {
// Serialize to the msgpack format
redis {
codec => msgpack
}
}
SpringBoot集成¶
Log4j2配置¶
1.pom.xml添加maven依赖¶
先上示例:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>
备注:
spring-boot-starter-web中集成了logback, 直接引用log4j2会发生包冲突, 导致debug会打印出红色警告日志
disruptor是英国最大交易机构LMAX开发的一个高性能队列, log4j2底层就采用了disruptor.
想要了解更多资料可以点击:
- 美团技术团队: https://tech.meituan.com/2016/11/18/disruptor.html
- 官方: https://github.com/LMAX-Exchange/disruptor/wiki/Introduction
2.resources目录下添加log4j2-spring.xml¶
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="OFF" monitorInterval="60">
<Appenders>
<!-- Console 日志,只输出 level 及以上级别的信息,并配置各级别日志输出颜色 -->
<Console name="Console" target="SYSTEM_OUT">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<!-- <PatternLayout pattern="%highlight{%d{yyyy.MM.dd 'at' HH:mm:ss z} %-5level %class{36} %M() @%L - %msg%n}{FATAL=Bright Red, ERROR=Bright Magenta, WARN=Bright Yellow, INFO=Bright Green, DEBUG=Bright Cyan, TRACE=Bright White}"/>-->
</Console>
<!-- socket 日志,输出日志到 Logstash 中做日志收集 -->
<Socket name="Socket" host="192.168.1.161" port="4560" protocol="TCP">
<JsonLayout properties="true" compact="true" eventEol="true" />
<PatternLayout pattern="%d{yyyy.MM.dd 'at' HH:mm:ss z} %-5level %class{36} %M() @%L - %msg%n"/>
</Socket>
</Appenders>
<Loggers>
<Root level="INFO">
<appender-ref ref="Socket"/>
<appender-ref ref="Console"/>
</Root>
</Loggers>
</Configuration>
3.准备logstash环境¶
a.下载对应es版本的logstash¶
curl https://artifacts.elastic.co/downloads/logstash/logstash-7.10.2-linux-x86_64.tar.gz
tar -zxvf logstash-7.10.2-linux-x86_64.tar.gz
b.配置conf¶
logstash中一个log4j2配置:
input {
tcp {
host => "192.168.1.161"
port => "4560"
mode => "server"
type => json
}
stdin {}
}
filter {
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.1.161:9200"]
user => "elastic"
password => "elastic123"
action => "index"
codec => rubydebug
index => "newlogstash"
}
}
c.添加插件¶
根据上述input/filter/output标签内使用的组件, 在logstash列表中添加
./bin/logstash-plugin list
./bin/logstash-plugin install logstash-input-tcp #这是一个示例
d.启动¶
./bin/logstash -f conf/log4j2-conf.conf
4.准备测试环境¶
一个controller控制器:
@RestController
@RequestMapping("Log")
@Log4j2
public class TestController {
@GetMapping("testLogMethod")
public String testLogMethod() {
log.info("this is a log of info level");
log.warn("warn log");
log.error("发生了错误");
return "hello, log system";
}
}
Logback配置¶
1.修改pom文件¶
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>2.0.0-alpha2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
2.resources目录下添加logback-spring.xml¶
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false">
<property name="LOG_HOME" value="logs/demo.log"/>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>192.168.1.161:4560</destination>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<!-- 可配置动态索引 [注意:自定义index名称必须小写]-->
<customFields>{"appname": "project-a"}</customFields>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT"/>
<appender-ref ref="logstash"/>
</root>
</configuration>
3.准备logstash环境¶
区别在于配置文件的修改, 只需要添加logback.conf:
input {
tcp {
host => "192.168.1.161"
port => "4560"
mode => "server"
# 使用下面这种方式 无法识别动态标签<customFields>
# type => json
codec => json_lines
}
stdin {}
}
filter {
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["192.168.1.161:9200"]
action => "index"
codec => rubydebug
index => "%{[appname]}-%{+YYYY.MM.dd}"
}
}
参考官方: https://github.com/logstash/logstash-logback-encoder#tcp-appenders
然后启动:
./bin/logstash -f config/logback.conf
4.准备测试环境¶
@RestController
@RequestMapping("Log")
@Slf4j
public class LogController {
@GetMapping("testLogMethod")
public String testLogMethod() {
log.debug("Logback: Debug log");
log.error("Logback: error");
return "hi, logback";
}
}
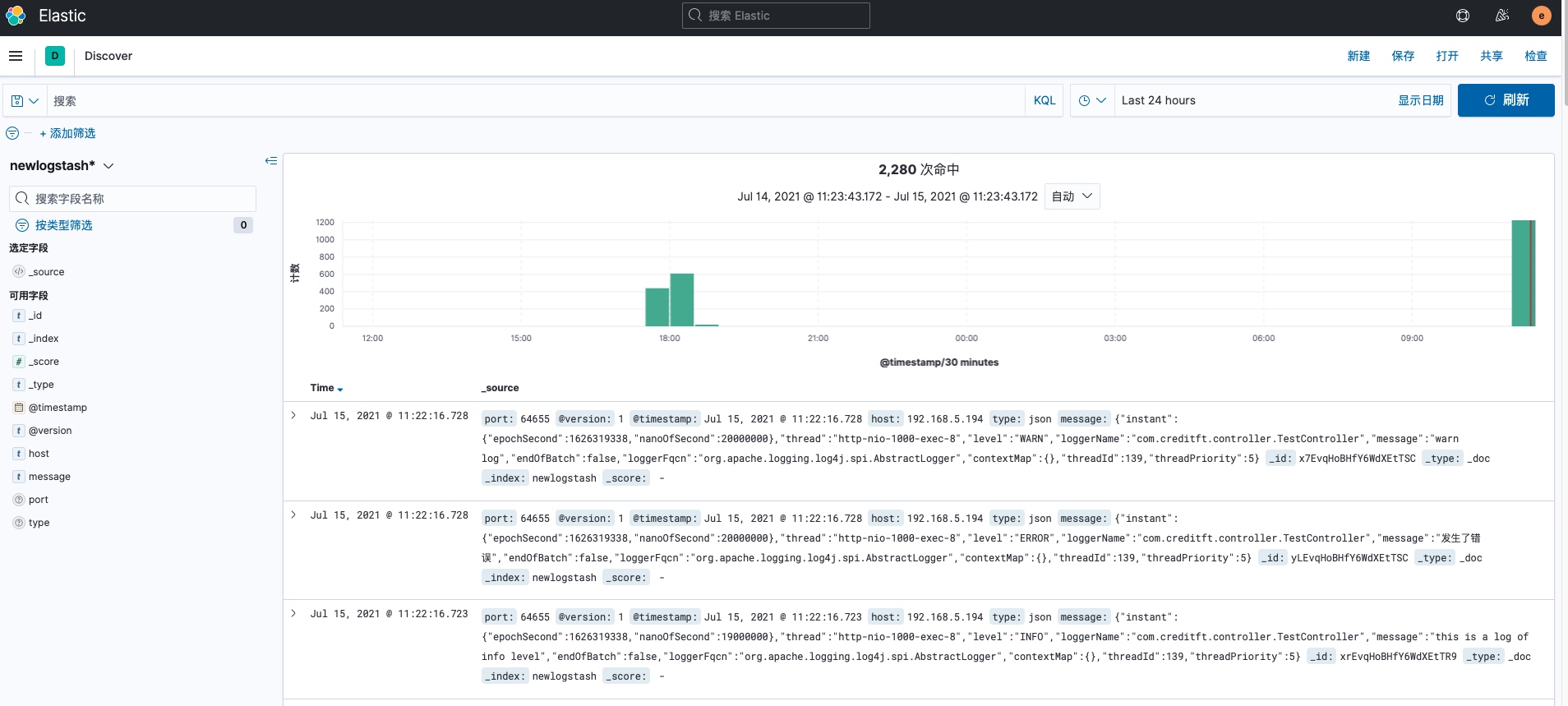
5.kibana展示¶
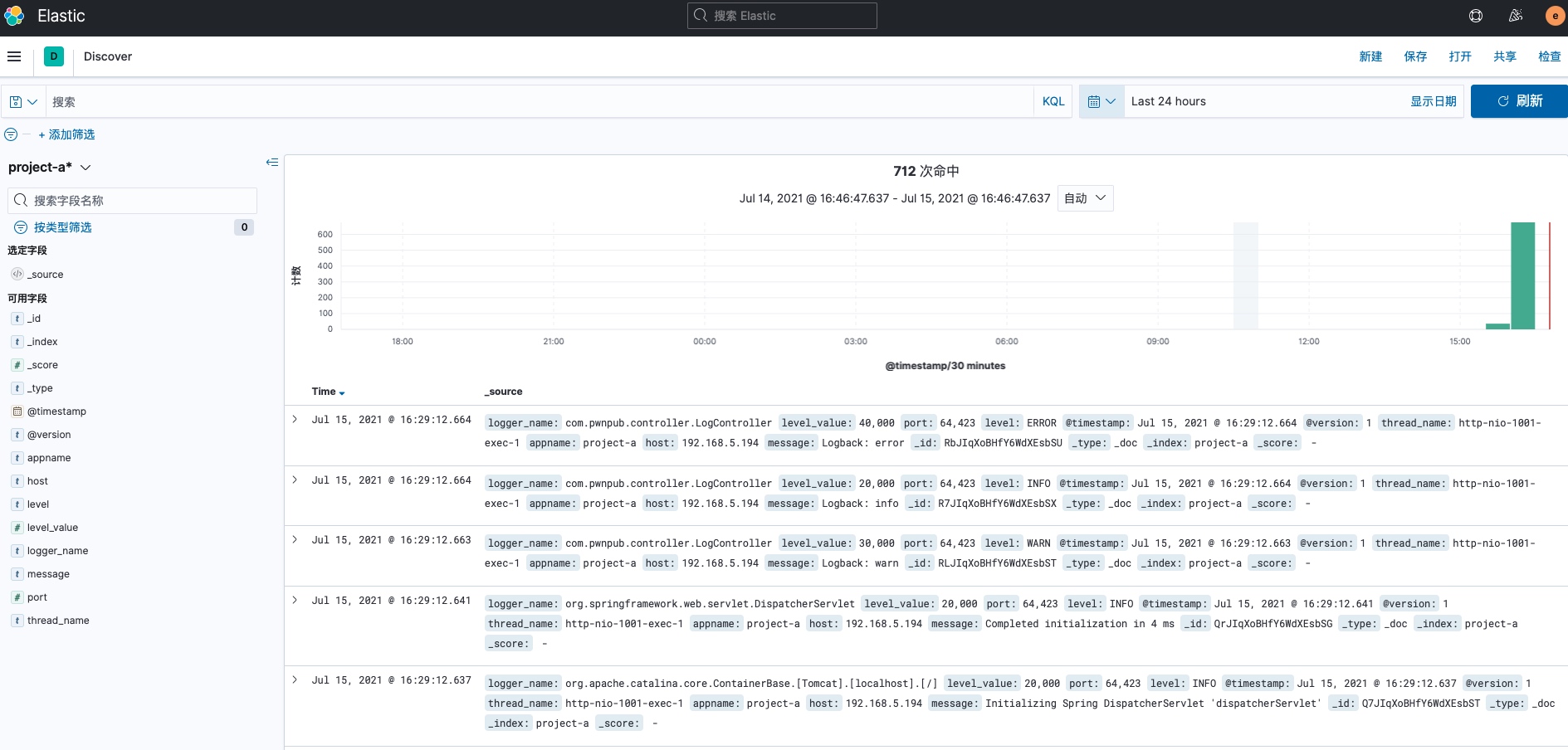
1.4. 轻量级插件¶
鉴于在服务端采集使用日志采用 Logstash 带来的额外的性能开销,可以引入 Filebeat 解决这一部分问题。 使用 Filebeat ,就是简化部分的 LogStash,Filebeat 是基于 logstash-forwarder 的源码改造而成,用 Golang 编写,无需依赖 Java 环境,效率高,占用内存和 CPU 比较少,非常适合作为 Agent 跑在服务器上。
Filebeats¶
轻量级logstash
接入指南¶
获取资源
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.2-linux-x86_64.tar.gz
解压
tar zxvf filebeat-7.10.2-linux-x86_64.tar.gz
修改配置文件
vim filebeat.yml
setup.kibana: host: "mykibanahost:5601" username: "my_kibana_user" password: "{pwd}" output.elasticsearch: hosts: ["localhost:9200"] username: "filebeat_internal" password: "YOUR_PASSWORD"
加载列表信息
./filebeat modules list
自定义加载关联组件
./filebeat modules enable mongodb system nginx kafka mysql
自动配置assets信息
./filebeat setup -e
-e is optional and sends output to standard error instead of the configured log output.
启动
./filebeat -e
use root run:
./filebeat -e –strict.perms=false
查看日志
如果没有异常信息,打开kibana -> discovery -> filebeat-*
自定义日志录入: 打开 filebeat.yml, update input or input stream, such as:
filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /var/log/*.log # update the path of your tomcat - /home/share/local-jar/startup.log
FAQ关于启动filebeat遇到的一些常见问题:
使用非root用户启动, 应当先授权目标用户的文件 744权限,如果权限过高, 则会启动失败;
使用root用户启动,则按照下方规则进行配置:
sudo chown root filebeat.yml sudo chown root modules.d/system.yml sudo ./filebeat -e
原理¶
一个基本配置¶
input {
beats { port => 5043 }
}
filter {
mutate { lowercase => ["message"] }
}
output {
elasticsearch { }
}
一个事件¶
- Logstash主要的数据单元就是事件
- 他们是文档类型, 和Json文档类型很相似,支持任意层次结构和类型
{
"@timestamp" => 2020-02-02T01-01-01,
"message" => "bar",
"some other field" => {
"has comflex values" => 123
}
}
一个管道¶
- pipelines 可伸缩
- 支持多个input
- 支持多个filter, output
- 一个Logstash,支持多个管道
队列和交付保障¶
| InMemoryQueue | Persistent Queue |
|---|---|
| 非常快 | 快 |
| 所有数据都在内存 | 收到的数据先落地磁盘,直到交付完成 |
| 没有落地 | 落地 |
| 正在处理的数据可能会因为非正常关闭而丢失 | 持久化,非正常关闭不会丢失数据 |
至少交付一次(At Least Once Delivery)¶
- 大部分插件支持
- 大部分情况,消息只交付一次
- 非正常关闭下,持久化队列里面的事件,我们可能会运行worker不止一次,可能会产生重复消息
- 幂等操作(永远写相同的ID)可以确保消息不重复
Packetbeat¶
- 实时抓取网络包
- 自动解析应用层协议
- 替代wireshark
Metricbeat¶
监控和管理¶
Monitoring
- 使用 Monitoring UI 集中监控和管理多个Logstash部署
- 通过Pipeline Viewer 快速定位和分析瓶颈
- 借助 Monitoring API 直接从Logstash节点获取节点指标信息
Pipeline Management
- 一个UI来管理多个Logstash节点上的多个管道
- Logstash可以轮询和动态重新加载更新的管道
- 使用X-Pack Security 特性来控制管道管理的访问
接入指南¶
- 同filebeat类似,详细内容参考filebeat接入指南
APM [application performance monitoring]¶
对于大部分应用程序来说性能都是很重要的一个因素,尤其对于比如网站、手机app等直接由用户访问的应用来说更是如此,因为性能较差的应用将会直接影响其用户体验。因此,能对应用进行性能监控变得非常重要,这将帮助我们找到性能瓶颈并优化。
应用性能监控(Application Performance Monitoring,APM),是对应用程序性能和可用性的监视和管理。 APM努力检测和诊断复杂的应用程序性能问题,以维持预期的服务等级。
APM Server¶
APM 服务器会从 APM 代理处接收数据,然后再将这些数据转换为 Elasticsearch 文档。 它是通过暴露 HTTP 服务器端点(代理会将所收集的 APM 数据流式传输到此端点)来实现这一点的。APM 服务器对来自 APM 代理的事件进行验证和处理之后,服务器会将数据转换为 Elasticsearch 文档,并将这些文档存储在相应的 Elasticsearch 索引中。
APM 代理¶
APM 代理是以您服务所用的相同语言编写的开源库。您可以像安装任何其他库一样,将 APM 代理安装到您的服务中。它们可以检测您的代码并在运行时收集性能数据和错误。这些数据会缓存一小段时间,然后发送到 APM 服务器。
APM 应用¶
查找并修复代码中存在的问题归根结底就是搜索。通过 Kibana 中的专用 APM 应用,您能够识别瓶颈并在代码层面准确定位到存在问题的地方。因此,您能够编写更好、更高效的代码,进而帮助您加快“开发-测试-部署”周期,让您的应用程序运行更快,客户体验更佳。
分布式跟踪¶
纳闷您的请求是如何流经整个基础架构的?通过分布式跟踪将所有内容整合到一起,清晰查看您的各项服务之间的交互情况。查找路径中哪个位置发生了延时问题,然后准确定位到需加以优化的组件。
效果:
- 对JVM的监控:
- 同时支持配置alerting阈值
APM接入指南¶
1. 下载elastic search 同版本 apm-server, 按照惯例, 官网¶
https://www.elastic.co/cn/downloads/past-releases#apm-server
找到对应版本, 执行
curl -L -O https://artifacts.elastic.co/downloads/apm-server/apm-server-7.10.2-linux-x86_64.tar.gz
2. 解压¶
tar -xvf apm-server-7.10.2-linux-x86_64.tar
3. 修改配置文件¶
cd apm-server-7.10.2-linux-x86_64
vim apm-server.yml
分别更新kibana、elasticsearch配置
# 更新kibana模块
kibana:
# For APM Agent configuration in Kibana, enabled must be true.
enabled: true
# Scheme and port can be left out and will be set to the default (`http` and `5601`).
# In case you specify an additional path, the scheme is required: `http://localhost:5601/path`.
# IPv6 addresses should always be defined as: `https://[2001:db8::1]:5601`.
host: "192.168.1.161:5601"
# Optional protocol and basic auth credentials.
#protocol: "https"
username: "elastic"
password: "elastic123"
# 更新elasticsearch模块
output.elasticsearch:
# Array of hosts to connect to.
# Scheme and port can be left out and will be set to the default (`http` and `9200`).
# In case you specify and additional path, the scheme is required: `http://localhost:9200/path`.
# IPv6 addresses should always be defined as: `https://[2001:db8::1]:9200`.
hosts: ["192.168.1.161:9200"]
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
username: "elastic"
password: "elastic123"
4.初始化配置¶
./apm-server setup
5.启动apm¶
./apm-server -c apm-server.yml
6.下载插件并启动java程序¶
先去 maven central 官网下载插件:https://search.maven.org/search?q=g:co.elastic.apm%20AND%20a:elastic-apm-agent
or 直接下载对应jar:
curl -L -O https://search.maven.org/remotecontent?filepath=co/elastic/apm/elastic-apm-agent/1.25.0/elastic-apm-agent-1.25.0.jar
然后启动java文件: (注意每个路径)
java -javaagent:/home/share/plugins/elastic-apm-agent-1.25.0.jar -Delastic.apm.service_name=my-cool-service -Delastic.apm.application_packages=org.example,org.another.example -Delastic.apm.server_url=http://localhost:8200 -jar hyperchain-0.0.1-SNAPSHOT.jar
1.5. ElasticSearch¶
启动单节点¶
下载压缩包、yum、apt、docker
配置单节点ES
elasticsearch.yml 单节点试验可以不用修改, 后面可以打开安全配置选项
配置缺省安全选项:添加
xpack.security.enabled: true
配置tcp通道加密:
xpack.security.transport.ssl.enabled: true xpack.security.transport.ssl.verification_mode: certificate xpack.security.transport.ssl.keystore.path: elastic-certificates.p12 xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
生成keystore和truststore
进入elasticsearch/bin目录, 将证书文件输出到config目录下
bin/elasticsearch-certutil cert -out config/elastic-certificates.p12 -pass “”
手动生成密码
bin/elasticsearch-setup-passwords interactive
配置kibana
kibana.yml
elasticsearch.hosts: [“http://localhost:9200”]
开启安全设置
从6.8、7.1开始免费提供基本安全设置
elasticsearch
elasticsearch.yml 添加:
xpack.security.enabled: true
设置缺省用户密码
- bin/elasticsearch-setup-passwords interactive
kibana
kibana.yml 打开注释,修改默认配置:
elasticsearch.username: “kibana” elasticsearch.password: “elastic123”
超级管理员: elastic elastic123 apm_system elastic123 kibana kibana123 ~ ~123
常用管理插件
- stack monitoring
- APM
- discovery
启动集群环境¶
配置文件¶
- node.master:表示节点是否具有称为主节点的资格
- true代表的是有资格竞选主节点
- false代表的是没有资格竞选主节点
- node.data:表示节点是否存储数据
3个节点配置如下:¶
node-1:
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
cluster.name: es-cluster
#
# ------------------------------------ Node ------------------------------------
#
node.name: node-1
node.master: true
node.data: true
#
# ----------------------------------- Paths ------------------------------------
#
path.logs: /home/share/es-logs
#
# ---------------------------------- Network -----------------------------------
#
# Set a custom port for HTTP:
#
http.port: 9200
transport.port: 9300
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
discovery.seed_hosts: ["192.168.1.161:9300", "192.168.1.162:9300", "192.168.1.163:9300"]
# Bootstrap the cluster using an initial set of master-eligible nodes:
cluster.initial_master_nodes: ["node-1"]
#discovery.type: single-node
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
node-2:
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
cluster.name: es-cluster
#
# ------------------------------------ Node ------------------------------------
#
node.name: node-2
node.master: true
node.data: true
#
# ----------------------------------- Paths ------------------------------------
#
path.logs: /home/share/es-logs
#
# ---------------------------------- Network -----------------------------------
#
# Set a custom port for HTTP:
#
http.port: 9200
transport.port: 9300
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
discovery.seed_hosts: ["192.168.1.161:9300", "192.168.1.162:9300", "192.168.1.163:9300"]
# Bootstrap the cluster using an initial set of master-eligible nodes:
# cluster.initial_master_nodes: ["node-1"]
#discovery.type: single-node
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
node-3:
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
cluster.name: es-cluster
#
# ------------------------------------ Node ------------------------------------
#
node.name: node-3
node.master: true
node.data: true
#
# ----------------------------------- Paths ------------------------------------
#
path.logs: /home/share/es-logs
#
# ---------------------------------- Network -----------------------------------
#
# Set a custom port for HTTP:
#
http.port: 9200
transport.port: 9300
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
discovery.seed_hosts: ["192.168.1.161:9300", "192.168.1.162:9300", "192.168.1.163:9300"]
# Bootstrap the cluster using an initial set of master-eligible nodes:
# cluster.initial_master_nodes: ["node-1"]
# discovery.type: single-node
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
Node组合¶
主节点+数据节点(master+data)
节点即有称为主节点的资格,又存储数据
node.master: true node.data: true
数据节点(data)
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false node.data: true
客户端节点(client)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候,可以进行负载均衡
node.master: false node.data: false
配置优化¶
写入性能优化策略:¶
- 用SSD
- 多线程bulk
- 尽量设置每个bulk的大小在5~15M左右
- 增加节点、分片
- 设置多个path.data目录,或配置RAID 0阵列
- 如果用的是SSD,设置index.store.throttle.type:none
- 禁用_all
- 增大index.refresh_interval的值,默认1s
- 增大index.translog.flush_threshold_size的值
- 设置0副本,建完索引优化后再增加副本
- 增大indices.memory.index_buffer_size的值
- 用比较新版本的ES
堆内存优化¶
建议配置¶
- 将Xms和Xmx设置为彼此相等, 具体原因可了解: GC触发器、GC触发条件等
- ElasticSearch可用的堆越多,可用于缓存的内存就越多
- 注意:太多的堆内存可能会导致长时间GC暂停
- 将Xmx设置为不超过可用物理内存的50%, 以确保有足够的物理内存留给服务器内核文件系统缓存
- Xmx设置不应超过32GB
如何配置¶
1.进入elasticsearch根目录, 在config/jvm.option 配置文件中设置:
-Xms4g -Xmx4g
2.注释掉jvm.option的Xms和Xmx设置, 启动时通过命令指定大小:
ES_JAVA_OPTS="-Xms2g -Xmx2g" ./bin/elasticsearch ES_JAVA_OPTS="-Xms4000m -Xmx4000m" ./bin/elasticsearch
问题抛晰¶
- 堆内存为什么不能超过物理机内存的一半?
堆对于Elasticsearch绝对重要。
它被许多内存数据结构用来提供快速操作。但还有另外一个非常重要的内存使用者:Lucene。
Lucene旨在利用底层操作系统来缓存内存中的数据结构。 Lucene段(segment)存储在单个文件中。因为段是一成不变的,所以这些文件永远不会改变。这使得它们非常容易缓存,并且底层操作系统将愉快地将热段(hot segments)保留在内存中以便更快地访问。这些段包括倒排索引(用于全文搜索)和文档值(用于聚合)。
Lucene的性能依赖于与操作系统的这种交互。但是如果你把所有可用的内存都给了Elasticsearch的堆,那么Lucene就不会有任何剩余的内存。这会严重影响性能。
标准建议是将可用内存的50%提供给Elasticsearch堆,而将其他50%空闲。它不会被闲置; Lucene会高兴地吞噬掉剩下的东西。
如果您不字符串字段上做聚合操作(例如,您不需要fielddata),则可以考虑进一步降低堆。堆越小,您可以从Elasticsearch(更快的GC)和Lucene(更多内存缓存)中获得更好的性能。
-- 来源: 官方
- 堆内存为什么不能超过32GB?
在Java中,所有对象都分配在堆上并由指针引用。普通的对象指针(OOP)指向这些对象,传统上它们是CPU本地字的大小:32位或64位,取决于处理器。
对于32位系统,这意味着最大堆大小为4 GB。对于64位系统,堆大小可能会变得更大,但是64位指针的开销意味着仅仅因为指针较大而存在更多的浪费空间。并且比浪费的空间更糟糕,当在主存储器和各种缓存(LLC,L1等等)之间移动值时,较大的指针消耗更多的带宽。
Java使用称为压缩oops的技巧来解决这个问题。而不是指向内存中的确切字节位置,指针引用对象偏移量。这意味着一个32位指针可以引用40亿个对象,而不是40亿个字节。最终,这意味着堆可以增长到约32 GB的物理尺寸,同时仍然使用32位指针。
一旦你穿越了这个神奇的〜32 GB的边界,指针就会切换回普通的对象指针。每个指针的大小增加,使用更多的CPU内存带宽,并且实际上会丢失内存。实际上,在使用压缩oops获得32 GB以下堆的相同有效内存之前,需要大约40-50 GB的分配堆。
以上小结为:即使你有足够的内存空间,尽量避免跨越32GB的堆边界。
否则会导致浪费了内存,降低了CPU的性能,并使GC在大堆中挣扎。
-- 来源: 官方
调整index_buffer_size¶
默认为堆内存的10%, 调整为堆内存的20%
indices.memory.index_buffer_size: 10%
调整建议:
- 必须在集群中的每个数据节点上进行配置。
- 缓存区越大,意味着能缓存数据量越大,相同时间段内,写盘频次低、磁盘 IO 小,间接提升写入性能。
OS配置优化¶
OS cache与ES memory swap¶
一:最好的办法是在系统上完全禁用交换。¶
这可以暂时完成:
sudo swapoff -a
要永久禁用它,你可能需要编辑你的 /etc/fstab。
二:控制操作系统尝试交换内存的积极性。¶
如果完全禁用交换不是一种选择,您可以尝试降低swappiness。该值控制操作系统尝试交换内存的积极性。这可以防止在正常情况下交换,但仍然允许操作系统在紧急内存情况下进行交换。
对于大多数Linux系统,这是使用sysctl值配置的:
vm.swappiness = 1
1的swappiness优于0,因为在某些内核版本上,swappiness为0可以调用OOM杀手。
三:mlockall允许JVM锁定其内存并防止其被操作系统交换。¶
最后,如果两种方法都不可行,则应启用mlockall。文件。这允许JVM锁定其内存并防止其被操作系统交换。在你的elasticsearch.yml中,设置这个:
1bootstrap.mlockall:true
内存锁:memory lock¶
Swapping is very bad for performance and for node stability and should be avoided at all costs. It can cause garbage collections to last for minutes instead of milliseconds and can cause nodes to respond slowly or even to disconnect from the cluster. – 来源官方
排查步骤:
1.先检查一下你的各个ES节点是否开启了Mem_lock
2.root权限执行ulimit -l unlimited
告诉操作系统可以无限制分配内存给一个进程
3.重新启动ES
ERROR: bootstrap checks failed memory locking requested for elasticsearch process but memory is not locked
4.遇到上述错误, 说明需要配置/etc/security/limits.conf
allow user ‘XXX’ mlockall XXX soft memlock unlimited XXX hard memlock unlimited
注: XXX 表示当前系统用户
注意
- 修改JVM相关配置很容易,但容易产生难以测量的不透明效果,并最终将您的群集解调为缓慢,不稳定的混乱
- 在调试群集时,第一步通常是删除所有自定义配置。大约一半的时间,仅靠这一点就恢复了稳定性和性能。
开发者快速接入¶
完成一套ELK/EFK的快速搭建, 将服务器日志 run.log 发送到 ElasticSearch, 并使用 Kibana 检索日志
配置¶
1.修改ES默认配置文件¶
$ vim elsticsearch.yml
cluster.name: es-single
node.name: node-1
node.master: true
node.data: true
http.port: 9200
transport.port: 9300
discovery.seed_hosts: ["192.168.1.161:9300"]
#cluster.initial_master_nodes: ["node-1"]
discovery.type: single-node
# 安全策略
# xpack.security.enabled: true
# xpack.security.transport.ssl.enabled: true
# xpack.security.transport.ssl.verification_mode: certificate
# xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
# xpack.security.transport.ssl.truststore.path: elastic-certificates.p12
2.修改filebeat配置¶
$ vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/workspace/run.log
setup.kibana:
host: "192.168.1.161:5601"
output.elasticsearch:
hosts: ["192.168.1.161", "192.168.1.162", "192.168.1.163"]
3.修改kibana配置文件¶
$ vim kibana.yml
server.port: 5601
server.host: "192.168.1.161"
server.name: "192.168.1.161"
elasticsearch.hosts: ["http://192.168.1.161:9200",
"http://192.168.1.162:9200",
"http://192.168.1.163:9200"]
kibana.index: ".kibana"